Bit rot, in case you do not know, is a scary word which makes you lose all confidence in your storage. To make it simple, it means that there is a slight chance that your data might change over time, getting corrupted. This leads to all sort of issues, especially with data which is not accessed often and not easily replaceable, if at all. Imagine losing your old family photos, movies of your kids, or the private key of your Bitcoin wallet...
Some theory
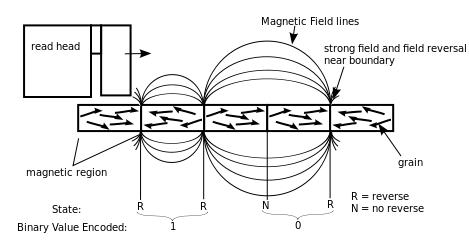 Space on hard disks is subdivided in sectors, and the density is so high that minimal degradations of the disk inevitably lead to corruption. Modern hard disks are smart enough to detect this problem, and silently replace corrupted sectors with new ones before they are unreadable (a new hard disk contain some amount of spare sectors, on top of the specified capacity, which are used for this). In simple words, this is what happens:
Space on hard disks is subdivided in sectors, and the density is so high that minimal degradations of the disk inevitably lead to corruption. Modern hard disks are smart enough to detect this problem, and silently replace corrupted sectors with new ones before they are unreadable (a new hard disk contain some amount of spare sectors, on top of the specified capacity, which are used for this). In simple words, this is what happens:
- The physical portion of a disk which correspond to a specific bit of your data is magnetized in a precise way, indicating whether that specific bit is a binary zero, or a one;
- When you access the data for reading, the hard disk head reads the data; if the magnetic field is still strong, all is good;
- If the magnetic field gets weaker (basically making a zero look more like a one or vice versa), the hard disk controller tries to magnetize it again;
- If, after this operation, there are still doubts, the sector is flagged as corrupted, and replaced with a new one from the spare pool (all data on the corrupted sector is moved to the new one while it's still readable).
This process has a weakness: what if you don't access your data for a long time? In this scenario, it is possible that a sector is accessed only when it's too late for the controller to clearly understand whether some of the bits stored there are actually zeros or ones. Given that a sector contains several bits, it is likely that many of them will be corrupted at the same time. In this case you have data corruption.
The reality is more complex than this, and hard disks store redundant information, which allows them to silently correct most errors. According to Wikipedia, in 2013, manufacturers claimed a non-recoverable error every $latex 10^{16}$ bits read (which is 1.25 Peta-bytes, or 1,250 TB). This is small, but not so small to make it totally irrelevant, and it is only for enterprise-grade hardware. I do not know if manufacturers publish these figures for consumer-grade disks, but you can assume that they are sensibly worse.
What can you do against bit rot
There are several things that can be done against this phenomenon, and all involve some amount of scrubbing (i.e. forcing the disk to read all the data stored on it periodically).
Simple scrubbing
This is the minimum protection that you can have. You just force the disk to periodically scrub its entire surface, hoping that no sectors could have gone bad since the last time you did that, and trusting the controller to move data to new sectors whenever necessary. While this should help, you have no way to know if problems are fixed, or even if there were problems in the first place: the hard disk controller will do its magic silently.
Data validation
In this case, you don't just read the data, but you validate all files to make sure they are still what they are supposed to be. You can do this using simple cryptographic hash functions, that you have computed and stored previously: SHA1 is probably [tooltip trigger="the most commonly used for this purpose" position="top" variation="slategrey"]As an example, git, one of the best known source code repository used by developers, uses SHA1 to detect whether a file has been modified.[/tooltip], it is fast and the probability of collision (i.e. two different files generating the same hash) is minimal. Hash collisions in this scenario are quite irrelevant anyway: given how cryptographic hashes work, for two different files to have the same hash, the files would have to be very different from each other. If the files differ by a couple of bits only, the hashes would necessarily be different, allowing you to detect the corruption easily.
Computing the SHA1 hash for a file is very easy, on OS X you can use the following command (which is actually a perl script) in the Terminal: shasum FILE_NAME (shasum has several options, you can check the man page for more details). If you want to do the same thing in ruby, you can use the following snippet (it can be done in one single line, but in this way you will read big files in chunks, to avoid filling up the memory):
[gist id="8314652" file="sha1.rb"]
This is not as trivial as it seems, because there are a number of files which change regularly, so you need to be smart enough to recognize and ignore them (possibly updating their hashes so they can be checked next time). In general files that change often are less at risk, the risk of bit rot being higher for files that are rarely accessed (read or written).
When you scrub your data and find a corrupted file, your only option is to restore it from a backup: the hash do not contain any redundant information allowing you to fix the corruption.
Advanced file systems
 There are file systems which automatically do all the above, and on top of that they store redundant parity information, which allows corrupted data to be corrected on the fly. These file systems periodically check that everything is in order, fixing issues. I am not a file system expert, and the only file systems doing this that I am aware of are ZFS and Btrfs. Apple was supposed to switch to ZFS for OS X a while back, but for some reasons this never happened. There are rumors according to which Apple is actually working on a new proprietary file system, with the same advanced features as ZFS. Anyway, this is not going to come tomorrow.
There are file systems which automatically do all the above, and on top of that they store redundant parity information, which allows corrupted data to be corrected on the fly. These file systems periodically check that everything is in order, fixing issues. I am not a file system expert, and the only file systems doing this that I am aware of are ZFS and Btrfs. Apple was supposed to switch to ZFS for OS X a while back, but for some reasons this never happened. There are rumors according to which Apple is actually working on a new proprietary file system, with the same advanced features as ZFS. Anyway, this is not going to come tomorrow.
Up to OS X 10.8 there used to be a great solution to use ZFS, from a company called GreenBytes. The name of this product is Zevo; unfortunately the company has decided to drop the product, which will not be updated to support the current OS X 10.9. There is a chance that GreenBytes is trying to sell their implementation to somebody else, or release it as open-source, but nothing confirmed, and again no time frame for this. There are also open source implementations of ZFS:
- MacZFS: stable, but not compatible with OS X 10.9, and feature limited;
- ZFS-OSX: "well-developed alpha", ready for testing; it is not feature complete yet, and they recommend not to trust it with any valuable data yet.
Trusting some hardware vendor
Drobo claims they are regularly scrubbing the disks to solve this issue (no on all their units though), but they do not give any detail on how this is done and how effective it is.
Probably other vendors in this space have similar claims, I have not done enough research to know for sure.
What can you concretely do today
![]() I am not sure I really got at the bottom of this yet, but the only real solution I have found today for OS X, without setting up a separate Linux file server with ZFS, is to periodically validate your files. Beside some half-backed apps on the Mac App Store, there is only one tool sufficiently advanced for this: IntegrityChecker, sold as part of diglloydTools. What I do not like of this package is that I need to buy two products useless to me, in order to get IntegrityChecker. Moreover, I would like to get more advanced features to help automate the entire process and just get a periodic report on with errors and warnings.
I am not sure I really got at the bottom of this yet, but the only real solution I have found today for OS X, without setting up a separate Linux file server with ZFS, is to periodically validate your files. Beside some half-backed apps on the Mac App Store, there is only one tool sufficiently advanced for this: IntegrityChecker, sold as part of diglloydTools. What I do not like of this package is that I need to buy two products useless to me, in order to get IntegrityChecker. Moreover, I would like to get more advanced features to help automate the entire process and just get a periodic report on with errors and warnings.
Conclusion
To get back to the title of this post: is bit rot myth or reality? I do not know, some people claim to have witnessed it, others claim that it's so unlikely to make it irrelevant. This said, I am now officially worried about the integrity of my data, and I do want to shed some light on this. I have decided to start actively monitoring the health of my important files. I might use IntegrityChecker, or I might roll my own tool (which you will see on OSOMac in a while if I manage to polish it sufficiently). Running this check for some time should give me a clear idea of the likelihood of data corruption, on top of allowing me to restore corrupted files from a backup; if the problem is really serious, I will probably invest in a small file server where I will use ZFS, which would give me peace of mind (this does not replace a proper backup strategy, of course).
That's all for now, more in the coming weeks if I decide to go ahead and develop something to check the integrity of files.